How We Optimized YARN Clusters Using Intelligent Overcommitment
YARN clusters often appear fully utilized on paper, but in reality, a significant portion of their capacity remains unused.
Applications tend to over-request resources to avoid failures, cluster schedulers operate on these requests rather than actual usage, and the default response to handle the scale of workload is to scale up the infrastructure, which results in more cost.
We wanted to challenge that assumption.
Instead of asking “How do we add more nodes?”, we asked: “How much unused capacity already exists in the cluster, and can we safely unlock it?”
This blog walks through the methodology we used to answer that question, along with the failures we encountered, what finally worked, and how we made the system robust enough for production environments.
Before We Begin
If you want a quick refresher on YARN architecture and scheduling, refer to: Yarn Docs
We’ll keep this discussion focused on optimization and not fundamentals.
The Real Problem: Allocated ≠ Actual Usage
YARN scheduling decisions are based on requested resources, not actual consumption.
In practice, this leads to a consistent gap between what is allocated and what is used.
Across clusters, this manifests as:
- Persistent idle CPU and memory
- Inefficient packing of workloads
- Artificial resource scarcity
This gap, called wastage, is the foundation of the optimization opportunity.
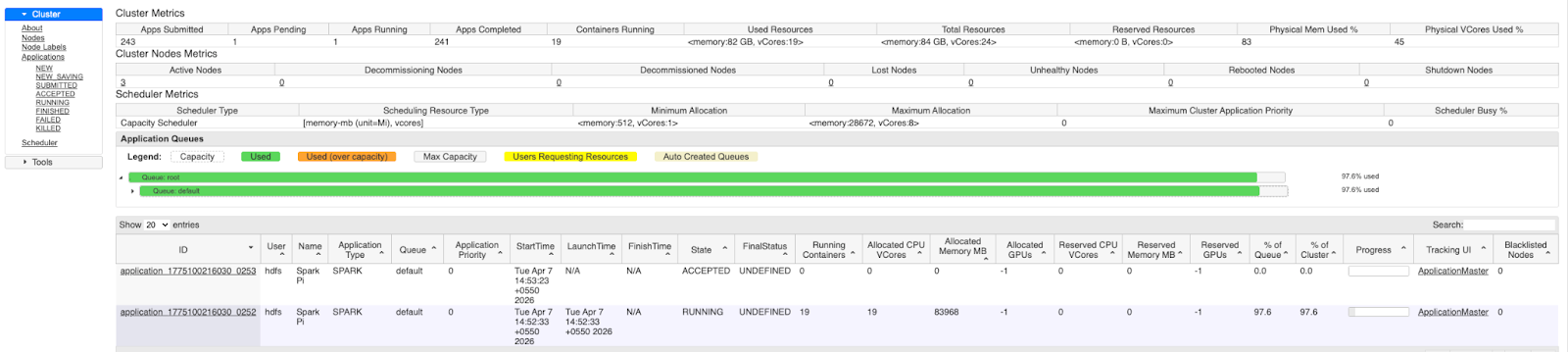
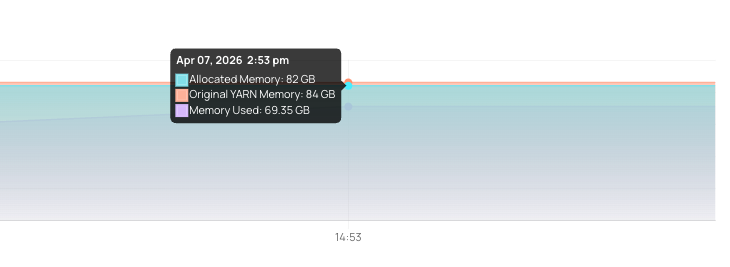
The image shows that the YARN UI indicates no resources are available for new applications. However, when we examine the actual usage of these NodeManagers using observability tools, we find that real consumption is significantly lower than the allocated resources. This observed usage also includes OS-level overhead, which means the actual unused capacity is even higher than it appears.
The Idea: Unlock Capacity Through Overcommitment
At a high level, the idea is simple:
If nodes are not fully utilized, allow them to run more workloads than their configured capacity.
However, applying this in a real cluster is far from trivial.
Overcommit too little, and the gains are negligible.Overcommit too aggressively, and you risk destabilizing nodes.
The problem is not enabling overcommitment — it is making it safe, adaptive, and reliable.
Early Attempts and Failures
Modifying the YARN Scheduler
Our initial approach was to directly modify the YARN scheduler to make smarter allocation decisions.
While technically feasible, it quickly became clear that this path was not viable:
- Tight coupling with YARN internals
- High maintenance overhead
- Upgrade and compatibility challenges
- Significant friction in adoption
Chasing the “Perfect” Overcommit Value
We then tried to compute precise overcommitment values based on observed usage.
This also failed.
Workloads are not deterministic; they spike, fluctuate, and evolve. A value that works today may break the system tomorrow.
We learned that precision is less important than adaptability and safety. So we can find the overcommitment value that can still allow some wastage (which is minimal) but does not compromise with the health of the nodes.
Node Instability and Failures
The most critical failures came from aggressive overcommitment:
- Memory spikes leading to OOM kills
- CPU contention is impacting latency-sensitive jobs
- NodeManagers are becoming unstable under pressure
This was the turning point.We realized that any optimization strategy must be built around failure prevention, not just efficiency gains.
Breaking Down the Problem
As we dug deeper, we realized that solving YARN optimization wasn’t a single problem — it was actually two distinct challenges.
First, we needed to identify how much of the allocated resources were truly unused.This meant reliably quantifying wastage based on actual runtime behavior rather than requested values.
Second, we needed to make YARN utilize this unused capacity without changing application behavior or introducing instability.
These two problems are tightly related, but they can be solved independently — and separating them made the overall approach much simpler and more practical.
To simplify the discussion, we start with the second problem.
Let’s assume for a moment that we already know how much extra capacity is available on each node.The question then becomes:
How do we expose this additional capacity to YARN so it can schedule more workloads?
Yarn exposes a command to override the resources of each Nodemanager at runtime. These resources get overridden to the original value once Nodemanager is restarted. This command can be utilized to solve the problem of exposing the additional resources to that specific node manager. Reference
Before: Node <hostname> had yarn resources of 28672 MB and 8 vcores
[user@<hostname> acceldata]# yarn node -list --showDetails
26/04/07 17:27:43 INFO client.RMProxy: Connecting to ResourceManager at <hostname>/<ip>:8050
26/04/07 17:27:44 INFO client.AHSProxy: Connecting to Application History server at <hostname>/<ip>:10200
26/04/07 17:27:44 INFO conf.Configuration: found resource resource-types.xml at file:/etc/hadoop/3.2.3.5-3/0/resource-types.xml
Total Nodes:1
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
<hostname>:45454 RUNNING <hostname>:8042 0
Detailed Node Information :
Configured Resources : <memory:28672, vCores:8>
Allocated Resources : <memory:0, vCores:0>
Resource Utilization by Node :
PMem:22278 MB, VMem:22278 MB, VCores:0.34321892
Resource Utilization by Containers :
PMem:0 MB, VMem:0 MB, VCores:0.0
After: Node <hostname> had yarn resources as 28700 MB and 9 vcores
[user@<hostname> acceldata]# yarn rmadmin -updateNodeResource <hostname>:45454 28700 9
26/04/07 17:39:19 INFO conf.Configuration: found resource resource-types.xml at file:/etc/hadoop/3.2.3.5-3/0/resource-types.xml
26/04/07 17:39:19 INFO client.RMProxy: Connecting to ResourceManager at <hostname>/<ip>:8141
[user@<hostname> acceldata]# yarn node -list --showDetails
26/04/07 17:39:25 INFO client.RMProxy: Connecting to ResourceManager at <hostname>/<ip>:8050
26/04/07 17:39:25 INFO client.AHSProxy: Connecting to Application History server at <hostname>/<ip>:10200
26/04/07 17:39:26 INFO conf.Configuration: found resource resource-types.xml at file:/etc/hadoop/3.2.3.5-3/0/resource-types.xml
Total Nodes:1
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
<hostname>:45454 RUNNING <hostname>:8042 0
Detailed Node Information :
Configured Resources : <memory:28700, vCores:9>
Allocated Resources : <memory:0, vCores:0>
Resource Utilization by Node :
PMem:22366 MB, VMem:22366 MB, VCores:0.7130956
Resource Utilization by Containers :
PMem:0 MB, VMem:0 MB, VCores:0.0
Once we understand how to integrate with YARN, we can shift focus to the harder problem:
How do we accurately determine the safe amount of overcommitment?
This is where things get interesting. There is no single correct value. The optimal overcommitment depends on workload behavior, node conditions, and how usage evolves.
Instead of relying on static configurations, we approached this as a data-driven estimation problem, where multiple signals are combined to make safe and adaptive decisions.
The Shift: From Static Optimization to Adaptive Intelligence
The breakthrough came when we stopped treating this as a static calculation problem and started treating it as a continuous learning and decision-making system.
Instead of asking:
“What is the right overcommit value?”
We reframed the problem as:
“How do we continuously estimate how much additional load a node can safely handle?”
What Actually Worked
We built a system that combines historical learning, real-time signals, and workload intelligence to make safe overcommitment decisions.
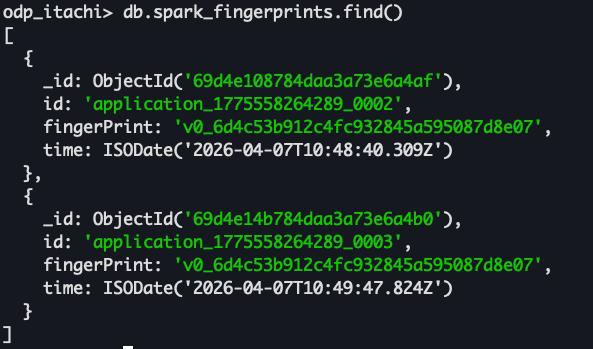
1. Workload Fingerprinting
Instead of treating each container independently, we grouped workloads based on behavioral similarity.
These fingerprints were specifically captured for jobs like Spark and Tez based on:
- Workload
- Job Resource Requests
- Hive/Spark configurations
This allowed us to move from reactive decisions to predictive understanding of workloads.
2. Pattern Recognition Over Time
Single observations are misleading.
We started analyzing usage across multiple runs to identify:
- Stable patterns
- Peak usage envelopes
- Variance and unpredictability
This helped us build confidence-aware estimates instead of naive averages.
3. Real-Time Analysis
Historical insights alone are not enough. At runtime, we continuously monitored:
- Current CPU and memory utilization for each node and container
- Short-term usage trends
- Historical peaks
This ensured that decisions were context-aware, not just historically driven.
4. Node Pressure Awareness
One of the most critical additions was incorporating node pressure signals into decision-making.
Instead of blindly applying overcommitment, we evaluated:
- CPU pressure and throttling
- Memory headroom
- System stress indicators
- Disk Pressure
- Network Pressure
We combine all these pressure metrics to generate a normalized score which is used to decide the optimum value. Overcommitment is allowed only when the node could safely absorb additional load.
Logs from Node pressure calculator :
2026/04/07 11:34:15 [MetricsEmitter] Emitted node pressure metrics for hostname=<hostname>, state=Focused, score=0.477267
2026/04/07 11:34:20 [NSPM] The node pressure status is as score 0.477267 for hostname <hostname>
2026/04/07 11:34:20 [MetricsEmitter] Emitted node pressure metrics for hostname=<hostname>, state=Focused, score=0.477267
2026/04/07 11:34:20 [NSPM] The node pressure status is as score 0.431411 for hostname <hostname>
2026/04/07 11:34:20 [MetricsEmitter] Emitted node pressure metrics for hostname=<hostname>, state=Focused, score=0.431411
2026/04/07 11:34:20 Node <hostname> has Allocated Memory 0.000000 , usedMemory by yarn containers 7915.671875 , allocated VCores 0.000000 and used VCores 3.782838
2026/04/07 11:34:20 Executing State Transition for <hostname> from Normal to Normal
5. QoS-Based Protection (Priority-Aware Stability)
Even with all safeguards, we observed that not all workloads are equal and not every time the calculated overcommitment results in a stable node. There may still be a possibility that a node tends towards instability.
To address this, we introduced a QoS (Quality of Service) layer into the optimization strategy. It uses the Yarn API to kill the container on that specific node, which might become unstable in the near future. This ensured that when a node started approaching instability:
- High-priority workloads were protected
- Lower-priority workloads were the first to be throttled, delayed, or reclaimed
- Resource contention did not impact critical applications
This was crucial because it shifted the system from: “avoid failure at all costs” → “manage degradation intelligently.” In other words, even under aggressive overcommitment, the system remained predictable and controlled.
6. Buffered and Safe Overcommitment
We used the combination of these features to calculate the overcommitment value for each node along with a leash to the user to control the optimizations. This ensured that optimization remained aggressive yet controlled.
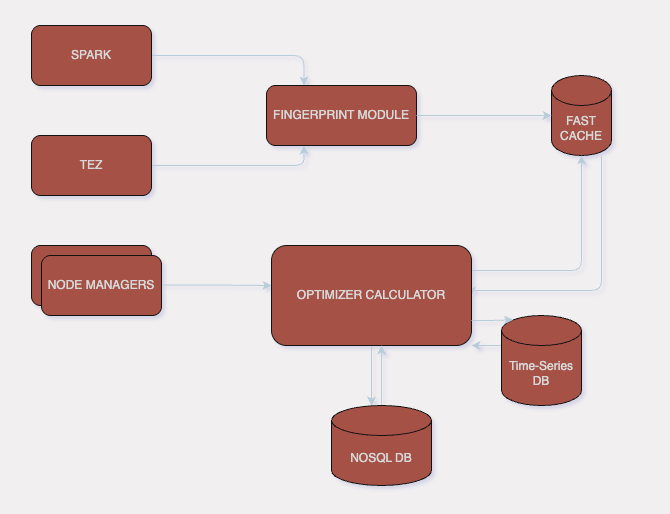
Bringing It All Together
What started as a simple idea evolved into a system with multiple reinforcing components:
- Fingerprinting for workload intelligence
- Pattern recognition for prediction stability
- Real-time monitoring for contextual awareness
- Node pressure analysis for safety
- Adaptive overcommitment for efficiency
These components work together to create a closed-loop optimization system — continuously learning, adjusting, and improving.
Results and ROI
With this approach, we observed the results as:
- 2× increase in container throughput
- ~30% improvement in application throughput
- 33% reduction in required nodes, which directly translates to money saved.
- Significant gains in CPU utilization
More importantly, these improvements were achieved without compromising stability.
Scaling YARN is often approached from the perspective of adding more and more nodes, more capacity, more infrastructure. But in our experience, the real opportunity lies in fully utilizing what already exists.
Check out a quick video here at the end for a closer look into this feature.
Working of Yarn Optimizer
Clusters are rarely truly saturated. More often, they are constrained by how resources are requested and perceived, not how they are actually used. By shifting the focus to real usage, and by safely unlocking unused capacity through intelligent overcommitment, it is possible to push clusters much closer to their true potential. The goal is not just optimization, it is maximizing effective capacity without compromising stability. When done right, this approach doesn’t just improve utilization metrics, it changes how we think about capacity planning altogether.
The most scalable cluster is not the one with the most resources, but the one that uses its resources the most effectively.