Agentic Data Management: Architecture, Agents, and Orchestration Explained
Part 2 of 2: The technical architecture behind Agentic Data Management
In Part 1, we explored why we built ADM and what capabilities it enables. Now let's dive into how it actually works.
How ADM Works: An Architectural Overview
Architecture Principles: ADM's architecture is built around three core principles:
- Specialized agents for domain expertise - Each agent is an expert in one aspect of data management
- Dynamic orchestration for scalability - Intelligent routing as the number of agents grows
- Abstraction layers for legacy integration - Bridging pre-2024 systems with modern AI
How Does It Work?
Step 1: Understanding the Query
Here's what happens when you ask ADM a question:
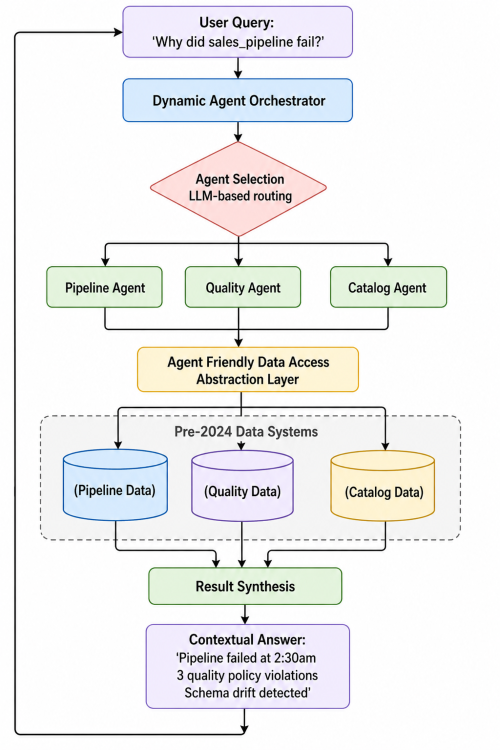
Step 2: Selecting Relevant Agents
ADM uses a multi-agent architecture where each agent is an expert in one domain:
- Catalog Agent: Asset metadata, schemas, ownership
- Quality Agent: Policy executions, quality scores, violations
- Pipeline Agent: DAG runs, task statuses, execution history
- Drift Agent: Schema changes, statistical anomalies
- Freshness Agent: Data update patterns, staleness detection
- Reconciliation Agent: Cross-system data consistency
We started with 5 specialized agents, now have 15+, and continue expanding as ADOC capabilities grow.
The scaling challenge: How do you select the right agents without loading everything for every query?
Our solution is dynamic agent selection using LLM-based routing:
class DynamicOrchestrator:
async def select_agents(self, query: str):
# LLM analyzes query and picks relevant agents
relevant_agents = await self.llm.route(
query=query,
available_agents=self.agent_registry
)
# Only initialize what's needed
return [self.load_agent(name) for name in relevant_agents]
This approach reduced our tool initialization time from 2.3s to 0.4s—critical for maintaining conversational response times.
Future experiments: We're exploring agent swarms (where multiple agents bid on tasks) and hierarchical orchestrators (meta-orchestrators that delegate to domain-specific coordinators) to scale beyond 50+ agents.
Step 3: Executing in Parallel
Once agents are selected, ADM executes them in parallel, not sequentially:
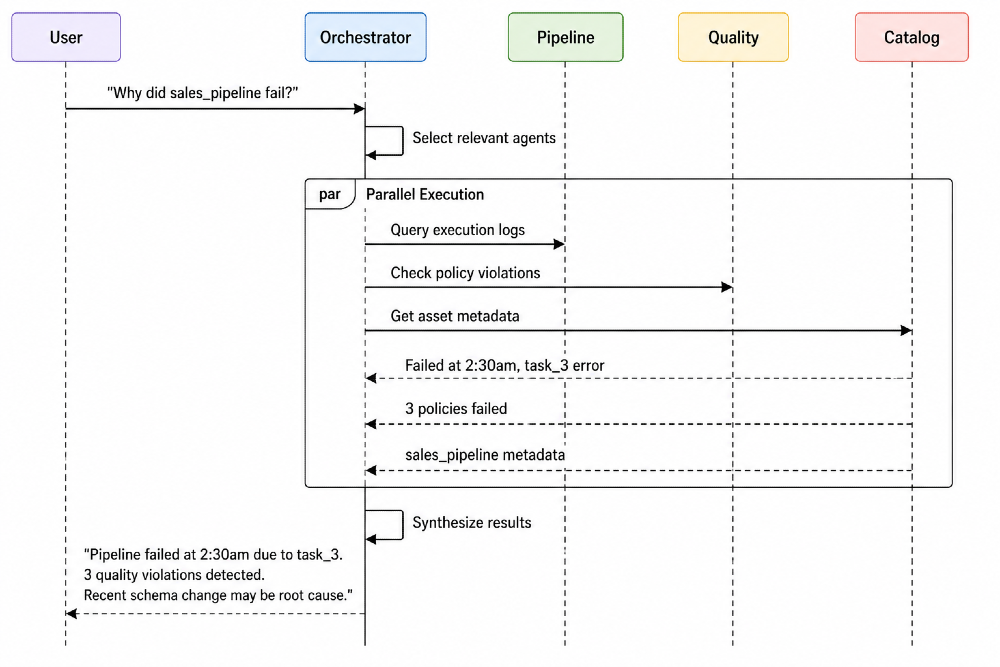
This parallel architecture keeps response times under 3 seconds even for complex multi-system queries.
Step 4: The Data Abstraction Layer
Critical design decision: How do you connect modern agentic AI to systems built before 2024?
ADOC's core infrastructure was designed years before LLMs became practical. The underlying systems weren't built with agent-friendly APIs. We needed an abstraction layer that:
- Exposes legacy data in a format agents can understand
- Provides semantic metadata (what fields mean, not just their types)
- Optimizes for agent query patterns (pre-joined views, not normalized tables)
Our solution: Semantic Data Layer
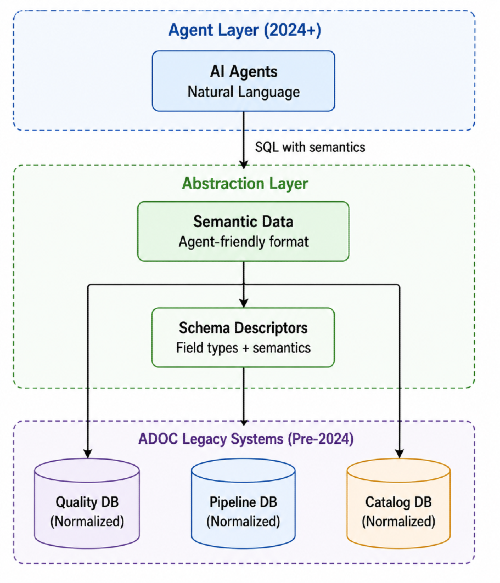
Each agent tool includes semantic descriptions that tell the LLM what's available:
class DataQualityTool(BaseSearchTool):
name: str = "data_quality_agent"
description: str = """
<quality_policy_executions>
-policy_id:id -policy_name:str -asset_name:str
-job_status:enum[SUCCESSFUL,FAILED,RUNNING]
-policy_score:num(0-100, higher=better)
-execution_started_at:timestamp
</quality_policy_executions>
"""
async def execute(self, query: str):
# Hits semantic views that bridge legacy and modern
return await self.api_client.query(query)
Key insight: This abstraction layer lets agents coexist with existing architecture without requiring a rewrite. Pre-2024 systems stay unchanged. Agents get the interface they need.
Why Is It Better?
1. Hybrid Scale-Out Architecture (Dataplane Integration)
This is the architectural differentiator. Most AI tools can observe and report. ADM can execute at scale.
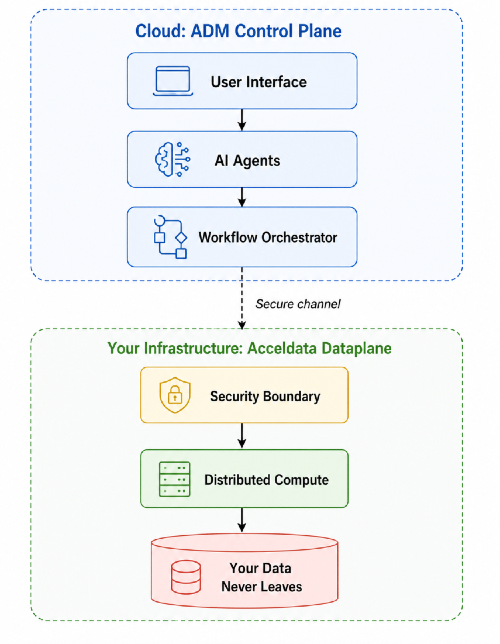
Key insight: The Dataplane deploys within your security perimeter. Data never leaves your environment, but you get cloud-scale AI orchestration.
This enables:
- Parallel policy deployment across thousands of assets
- Large-scale remediation without impacting production
- Compliance preservation while leveraging AI capabilities
2. Model Context Protocol (MCP) Integration
ADM provides complete MCP support, creating a unified intelligence layer across your entire tech stack:
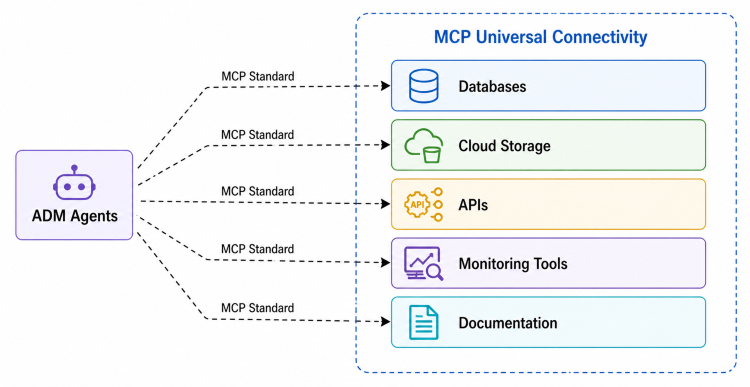
Impact: When investigating an issue, ADM can correlate data quality metrics with application logs, support tickets, and historical documentation—all through standardized MCP connectors.
3. Enterprise Security & Multi-Tenancy
All standard enterprise requirements are first-class architectural concerns, not afterthoughts.
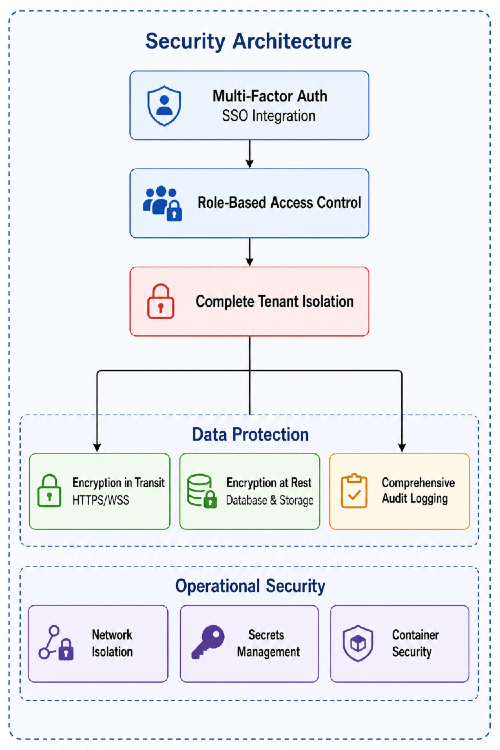
4. Hallucination Prevention
This nearly killed the project in early testing. The LLM would confidently report pipelines that didn't exist or quality scores it invented.
Example of the problem:
User: "Show me quality scores for customer_revenue table"
Early ADM: "customer_revenue has a quality score of 87.5 with 3 active policies"
Reality: customer_revenue table doesn't exist in the system
Our solution is architectural, not just prompt engineering:
# System-level constraint
HALLUCINATION_PREVENTION = """
When tool calls return EMPTY or NO results, NEVER fabricate data.
Every entity name, ID, or metric must come from actual tool results.
Inventing data is worse than returning no data.
"""
# Plus:
# - Structured tool outputs (typed responses)
# - Schema enforcement (agents can't query non-existent fields)
# - Result verification layer (validates all returned entities exist)
Measured impact: This reduced hallucinations from 15% of responses to <0.5%—critical for enterprise trust.
Example of the fix:
User: "Show me quality scores for customer_revenue table"
Current ADM: "I found 0 assets matching 'customer_revenue'.
Did you mean: customer_revenue_daily, customer_revenue_monthly?"
The system now suggests alternatives based on actual data rather than inventing results.
Architecture Takeaways
ADM's innovation isn't in chat—it's in the architectural integration of:
- Agentic orchestration for intelligent task routing
- Dynamic agent selection scales with growing capabilities
- Parallel execution maintains conversational response times
- LLM-based routing adapts to new agents without code changes
- Hybrid compute for scale-out execution without data movement
- Dataplane runs in customer infrastructure for security
- Cloud orchestration provides AI intelligence
- Best of both worlds: security + capability
- Universal connectivity through MCP for cross-system intelligence
- Standardized connectors to any data source
- Cross-platform correlation for incident investigation
- Knowledge base integration for contextual responses
- Enterprise security as a foundational design principle
- Multi-tenancy from day one
- Complete audit trails for compliance
- Hallucination prevention for trust
We didn't replace ADOC. We added a conversational control plane that makes 6 years of sophisticated data observability accessible to anyone who can ask a question.
Technical Stack
- Backend: Python/FastAPI with async/await throughout
- Agent Framework: LangChain for orchestration and tool calling
- Data Layer: PostgreSQL with optimized semantic views
- Real-time: Redis + WebSockets for multi-user collaboration
- LLM Providers: OpenAI, Anthropic, AWS Bedrock (multi-provider support)
- Execution: Acceldata Dataplane for distributed compute
This is Part 2 of our ADM series. Read Part 1: Why We Built ADM for the strategic context and use cases.